Apr 18 2024

I’ve been on the lookout for a ethernet switch that I don’t hate, the problem with a lot of higher speed (10G and above) ethernet switches is that they are quite expensive new and if you buy the used then they rarely have many years left ( or none at all ) of software patches.
A lot of the low end market for ethernet switches also have infamously bad software and one of the things that annoys me the most about the networking industry as a whole is that a lot of the cheap equipment has no real way of doing software support yourself.
So, I was very happy to learn that a friend had a Mellanox SN2010 that they were not using and were willing to sell to me. The SN2010 (Or the HP branded SKU that I picked up SN2010M) is a 18xSFP28 (25gbit) and 4xQSFP28 (100gbit) switch that instead of being your typical switch that uses a broadcom chipset for the data plane ( the bit that actually switches the packets ), uses Mellanox’s (now nvidia) own silicon. The massive benefit of this is that the drivers (mlxsw) for the Mellanox chip are open to people who don’t want to pay large volumes of money for a SDK, unlike the broadcom counterparts.
So I took a punt, and bought it.

The goal that I now have is to run this relatively cheap (and power efficient at 60W) switch with as close to stock Debian as possible. That way I do not have to lean on any supplier for software updates, and I can upgrade software on the switch for as long as I need it. This does mean however that the bugs will be my responsibility (since there is no TAC to fall back on).
A lot of the stuff I am going to present will be similar to Pim’s research for a similar SN2700 but I will focus on how I’ve deployed my setup, now that I’ve been running this setup for some time in production without any hitches. Like the SN2700 is a 32x 100G port device, newer, larger and faster versions of these switches are also available.
First though, let’s take a peek…

Here we see two reasonably integrated 12V DC power supplies. They are not hot swappable, however in my production experience so far I have not encountered a PSU failure where a hot swap unit would have been useful. So that is not a production concern to me.
In addition the fan tray can easily be swapped around, meaning you can easily transition this from being a Ports-to-Power airflow to Power-to-Ports airflow. I use the switch in Power-to-Ports as it’s easier to access the optical ports from the back of the rack than the front for my use case.
One thing of note while we have the lid open, Inside of the switch is a mystery QSFP connector with no cage, I’m unsure what it is used for, but I’m not willing to risk sticking an optic in it and find out!

Because the switch is sold under “open networking” it comes with the ONIE installation system.
My previous experience with ONIE suggests that it is not going to be incredibly useful for our use case, so we will not be using it, instead opting for a more SN2010 specific method. If you squint, this switch basically looks like a laptop with an absolutely massive network card installed into it:
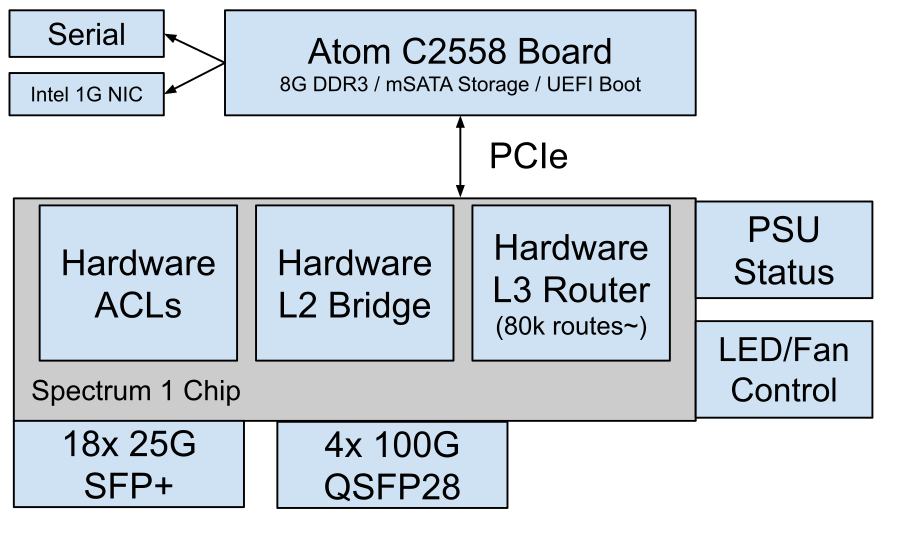
So we can just install Debian on it as if it was a laptop. So first, we need to get into the firmware/BIOS of the switch.
First you will need (really) a USB Keyboard to get into the BIOS, when the switch boots up mash F7, if you are lucky Ctrl+B will work over the serial console, but do not count on this working.
If you have done this correctly a BIOS password prompt will show up, the BIOS password is typically “admin”
Once you are into the BIOS you can remove the USB keyboard and replace it with a USB drive with a debian netinstall, then using the serial console navigate to the EFI Shell to boot grub from the USB drive.
Play recording
When you get to grub you need to teach the installer about the serial console, since it will be critical for you to be able to install from, you can do this by adding “console=tty0 console=ttyS0,115200” to the end of the boot options.
Once you have done that, you can proceed with a normal debian install, you will only see one NIC for now, since that is the built in NIC from the Intel Atom SOC that is the “management” ethernet port next to the serial console
Once you have finished installing, you will need to also apply the same “console=tty0 console=ttyS0,115200” into your boot options on first boot, and then set that up to be a permanent grub configuration.
Now that we have a working debian system, we can observe that we only currently have a single NIC, but we do have a mystery PCI device.
# lspci
00:00.0 Host bridge: Intel Corporation Atom processor C2000 SoC Transaction Router (rev 03)
00:01.0 PCI bridge: Intel Corporation Atom processor C2000 PCIe Root Port 1 (rev 03)
00:02.0 PCI bridge: Intel Corporation Atom processor C2000 PCIe Root Port 2 (rev 03)
00:03.0 PCI bridge: Intel Corporation Atom processor C2000 PCIe Root Port 3 (rev 03)
00:0b.0 Co-processor: Intel Corporation Atom processor C2000 QAT (rev 03)
00:0e.0 Host bridge: Intel Corporation Atom processor C2000 RAS (rev 03)
00:0f.0 IOMMU: Intel Corporation Atom processor C2000 RCEC (rev 03)
00:13.0 System peripheral: Intel Corporation Atom processor C2000 SMBus 2.0 (rev 03)
00:14.0 Ethernet controller: Intel Corporation Ethernet Connection I354 (rev 03)
00:16.0 USB controller: Intel Corporation Atom processor C2000 USB Enhanced Host Controller (rev 03)
00:17.0 SATA controller: Intel Corporation Atom processor C2000 AHCI SATA2 Controller (rev 03)
00:18.0 SATA controller: Intel Corporation Atom processor C2000 AHCI SATA3 Controller (rev 03)
00:1f.0 ISA bridge: Intel Corporation Atom processor C2000 PCU (rev 03)
00:1f.3 SMBus: Intel Corporation Atom processor C2000 PCU SMBus (rev 03)
01:00.0 Ethernet controller: Mellanox Technologies MT52100
To allow the switch to command the switch chip and see the other front panel ports we will need to use a kernel that has the mlx-core module, this module is not compiled with the “stock” debian kernels.
This is a case of ensuring the following modules in the kernel build config are set:
Click to expand to see kernel options
CONFIG_NET_IPIP=m
CONFIG_NET_IPGRE_DEMUX=m
CONFIG_NET_IPGRE=m
CONFIG_IPV6_GRE=m
CONFIG_IP_MROUTE_MULTIPLE_TABLES=y
CONFIG_IP_MULTIPLE_TABLES=y
CONFIG_IPV6_MULTIPLE_TABLES=y
CONFIG_BRIDGE=m
CONFIG_VLAN_8021Q=m
CONFIG_BRIDGE_VLAN_FILTERING=y
CONFIG_BRIDGE_IGMP_SNOOPING=y
CONFIG_NET_SWITCHDEV=y
CONFIG_NET_DEVLINK=y
CONFIG_MLXFW=m
CONFIG_MLXSW_CORE=m
CONFIG_MLXSW_CORE_HWMON=y
CONFIG_MLXSW_CORE_THERMAL=y
CONFIG_MLXSW_PCI=m
CONFIG_MLXSW_I2C=m
CONFIG_MLXSW_MINIMAL=y
CONFIG_MLXSW_SWITCHX2=m
CONFIG_MLXSW_SPECTRUM=m
CONFIG_MLXSW_SPECTRUM_DCB=y
CONFIG_LEDS_MLXCPLD=m
CONFIG_NET_SCH_PRIO=m
CONFIG_NET_SCH_RED=m
CONFIG_NET_SCH_INGRESS=m
CONFIG_NET_CLS=y
CONFIG_NET_CLS_ACT=y
CONFIG_NET_ACT_MIRRED=m
CONFIG_NET_CLS_MATCHALL=m
CONFIG_NET_CLS_FLOWE=m
CONFIG_NET_ACT_GACT=m
CONFIG_NET_ACT_MIRRED=m
CONFIG_NET_ACT_SAMPLE=m
CONFIG_NET_ACT_VLAN=m
CONFIG_NET_L3_MASTER_DEV=y
CONFIG_NET_VRF=m
If you are not able to compile a kernel yourself, and you can try with my pre-compiled kernels (that come with zero support/security updates/guarantee) here: https://benjojo.co.uk/fp/mlx-sw-kernel-debs.tar
The Linux kernel driver is expecting a specific version of firmware to be running on the switch chip, so after you reboot with the new kernel you might still not have all of the interfaces. You can look in dmesg for something like:
[ 7.168728] mlxsw_spectrum 0000:01:00.0: The firmware version 13.1910.622 is incompatible with the driver (required >= 13.2010.1006)
We can get these firmware blobs from https://switchdev.mellanox.com/firmware/, and extract them to /usr/lib/firmware/mellanox, for example the file path for the above dmesg line should be /usr/lib/firmware/mellanox/mlxsw_spectrum-13.2010.1006.mfa2, once you have put it there you may also want to run update-initramfs -u -k all and reboot and wait (for at least 10 mins) for the driver to automatically upgrade the chip firmware.
If you are running HPE or Catchpoint SKUs of this switch, the kernel driver may fail to upgrade the firmware with something like:
mlxfw: Firmware flash failed: Could not lock the firmware FSM, err (-5)
If you encounter this try compiling and using the user space tool and running the upgrade manually
$ mstfwmanager -d 01:00.0 -i mlxsw_spectrum-13.2000.2308.mfa -f -u
If successful, the upgrade should look like:
Device #1:
----------
Device Type: Spectrum
Part Number: Q9E63-63001_Ax
Description: HPE StoreFabric SN2010M 25GbE 18SFP28 4QSFP28 Half Width Switch
PSID: HPE0000000025
PCI Device Name: 01:00.0
Base MAC: 1c34daaaaa00
Versions: Current Available
FW 13.1910.0622 13.2010.1006
Status: Update required
---------
Found 1 device(s) requiring firmware update...
Device #1: Updating FW ...
[4 mins delay]
Done
Restart needed for updates to take effect.
Assuming the upgrade succeeds, reboot the switch and you should see a extra 20 network interfaces appear in ip link
You can double check your chip versions by running:
# devlink dev info
pci/0000:01:00.0:
driver mlxsw_spectrum
versions:
fixed:
hw.revision A1
fw.psid HPE0000000025
running:
fw.version 13.2010.1006
fw 13.2010.1006
You will likely want to apply udev rules to ensure these interfaces are named in a way that makes a bit more sense, otherwise you can physically locate each port by blinking their port LEDs with ethtool -m swp1
I use the udev rules from Pim’s guide on the SN2700:
# cat << EOF > /etc/udev/rules.d/10-local.rules
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="mlxsw_spectrum*", \
NAME="sw$attr{phys_port_name}"
EOF
Once you reboot your front panel switch interface names should now be swp* interfaces that should match roughly with the numbers on the front.
If you are ever unsure what you are port you are looking at on the CLI you can “eyeball” what port is what by using the port speed indicator from ethtool, for example, a 100G QSFP28 port looks like:
root@bgptools-switch:~# ethtool swp20
Settings for swp20:
Supported ports: [ FIBRE ]
Supported link modes: 1000baseKX/Full
10000baseKR/Full
40000baseCR4/Full
40000baseSR4/Full
40000baseLR4/Full
25000baseCR/Full
25000baseSR/Full
50000baseCR2/Full
100000baseSR4/Full
100000baseCR4/Full
100000baseLR4_ER4/Full
These ports can be configured as you would a normal “software” linux router interface, complete with the routing table as well. Except most configuration you are providing to linux is automatically replicated to the ASIC for you. In my case I will use ifupdown to manage my interface configuration, as it is the easiest for me to debug if it ever goes wrong.
This allows you to have 800Gbits+ of capacity managed by a 4 Core Intel Atom CPU!
Now that we have a working router, we can just set things up like we would a normal Linux “soft” router, except this swooter (a name I use for a switches that function as IP routers as well) can copy the setup we build inside of Linux, and put it into a data plane capable of multiples of 100 Gbit/s.
For the sake of this post, I will go over the setup I’ve been running in production to show you what this switch has to offer:
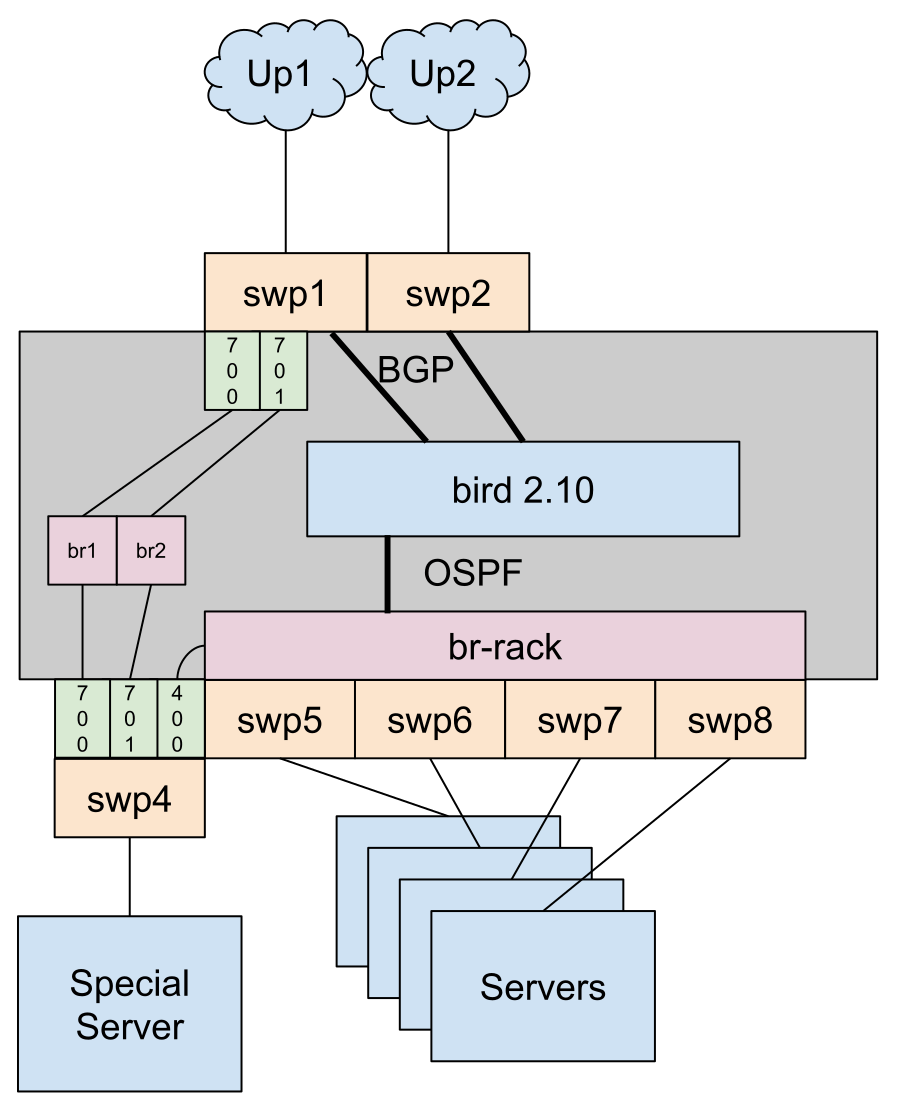
I have two uplink ports from my provider, they are VLAN tagged with a DIA/Internet with point to point addresses (/31 for IPv4, /127 for IPv6) that have BGP on them. There are a number of other IP services that are delivered using different VLANs on one of the provider ports.
In my previous setup I would be doing BGP on one of the servers, but the switch can handle both of these BGP sessions. However it’s worth knowing that the switch cannot handle “full” internet BGP tables, but I requested that my provider send IPv4 and IPv6 default routes on both BGP sessions to solve that problem.
In my previous setup, all of my servers sat in a private production VLAN with OSPF coordinating the IP addressing between them. Since I don’t want to change too many things at once. I’ve replicated the same thing by chaining most servers ethernet ports into a newly made “br-rack” Linux Bridge
There is however one server that needs this bridge in a VLAN, however that is fine since you can just make a linux VLAN interface and add that to the bridge and the driver will automatically figure this out.
Using ifupdown language, this is what the port configuration looks like in /etc/network/interfaces:
auto swp4
iface swp4 inet manual
iface swp4 inet6 manual
auto swp4.400 # "Rack LAN"
auto swp4.700 # Service1
auto swp4.701 # Service2
auto br-rack0
iface br-rack0 inet static
bridge_hw swp5
bridge-ports swp4.400 swp5 swp6 swp7 swp8 swp9 swp10
bridge_stp off
bridge_waitport 0
bridge_fd 0
address 185.230.223.xxx/28
post-up ip l set dev br-rack0 type bridge mcast_snooping 0
iface br-rack0 inet6 static
dad-attempts 0
address 2a0c:2f07:4896:xxx/120
You will want to ensure you have set bridge mcast_snooping 0 if you plan on using OSPF, as if you have snooping enabled without extra services running on the switch, multicast traffic (including OSPF) can be disrupted.
You will also want to set bridge_hw to a switch port of your choice. Due to hardware limitations the switch chip has to use 1 range of MAC addresses for things that relate/route to it. So the bridge_hw option just “steals” the MAC address of a port and uses that for the bridge.
At this point you can just configure BGP and OSPF as you normally would, and install/export the routes into the kernel, However since the hardware can only hold around 80,000 routes some care needs to be taken to ensure that you only “install” your own Internal/OSPF routes and your provider BGP default routes.
For example, my own bird config looks like:
protocol kernel {
merge paths on;
ipv4 {
export filter {
if net ~ [0.0.0.0/0{0,0},185.230.223.0/24{24,32}] || source = RTS_OSPF || source = RTS_OSPF_EXT2 || source = RTS_OSPF_EXT1 then {
accept;
}
reject;
};
};
}
The merge paths on option allows the switch to ECMP over routes, useful for your default routes
root@bgptools-switch:~# ip route
default proto bird metric 32 rt_offload
nexthop via 192.0.2.1 dev swp1.600 weight 1 offload
nexthop via 192.0.2.2 dev swp2.601 weight 1 offload
198.51.100.0/28 via 185.230.223.xxx dev br-rack0 proto bird metric 32 offload rt_offload
203.0.113.0/24 via 185.230.223.xxx dev br-rack0 proto bird metric 32 offload rt_offload
It is worth pointing out that you should also setup a sane and sensible SSH policy and firewalling. You could easily just apply the same solution that you use for your servers. Like Salt/Chef/Puppet/Ansible, after all, this is just like a server with a magic NIC in it!
There are also some good linux sysctl options you should set to make your swooter act more like a hardware router is expected to. As per the mlxsw wiki recommends:
Click to expand to see sysctls
# Enable IPv4 and IPv6 forwarding.
net.ipv4.ip_forward=1
net.ipv6.conf.all.forwarding=1
net.ipv6.conf.default.forwarding=1
# Keep IPv6 addresses on an interface when it goes down. This is
# consistent with IPv4.
net.ipv6.conf.all.keep_addr_on_down=1
net.ipv6.conf.default.keep_addr_on_down=1
# Prevent the kernel from routing packets via an interface whose link is
# down. This is not strictly necessary when a routing daemon is used as
# it will most likely evict such routes. In addition, when offloaded,
# such routes will not be considered anyway since the associated neighbour
# entries will be flushed upon the carrier going down, preventing the
# device from determining the destination MAC it should use.
net.ipv4.conf.all.ignore_routes_with_linkdown=1
net.ipv6.conf.all.ignore_routes_with_linkdown=1
net.ipv4.conf.default.ignore_routes_with_linkdown=1
net.ipv6.conf.default.ignore_routes_with_linkdown=1
# Use a standard 5-tuple to compute the multi-path hash.
net.ipv4.fib_multipath_hash_policy=1
net.ipv6.fib_multipath_hash_policy=1
# Generate an unsolicited neighbour advertisement when an interface goes
# down or its hardware address changes.
net.ipv6.conf.all.ndisc_notify=1
net.ipv6.conf.default.ndisc_notify=1
# Do not perform source validation when routing IPv4 packets. This is
# consistent with the hardware data path behavior. No configuration
# is necessary for IPv6.
net.ipv4.conf.all.rp_filter=0
net.ipv4.conf.default.rp_filter=0
# Do not update the SKB priority from "TOS" field in IP header after
# the packet is forwarded. This applies to both IPv4 and IPv6 packets
# which are forwarded by the device.
net.ipv4.ip_forward_update_priority=0
# Prevent the kernel from generating a netlink event for each deleted
# IPv6 route when an interface goes down. This is consistent with IPv4.
net.ipv6.route.skip_notify_on_dev_down=1
# Use neighbour information when choosing a nexthop in a multi-path
# route. Will prevent the kernel from routing the packets via a
# failed nexthop. This is consistent with the hardware behavior.
net.ipv4.fib_multipath_use_neigh=1
# Increase the maximum number of cached IPv6 routes. No configuration is
# necessary for IPv4.
net.ipv6.route.max_size=16384
# In case the number of non-permanent neighbours in the system exceeds
# this value for over 5 seconds, the garbage collector will kick in.
# Default is 512, but if the system has a larger number of interfaces or
# expected to communicate with a larger number of directly-connected
# neighbours, then it is recommended to increase this value.
net.ipv4.neigh.default.gc_thresh2=8192
net.ipv6.neigh.default.gc_thresh2=8192
# In case the number of non-permanent neighbours in the system exceeds
# this value, the garbage collector will kick in. Default is 1024, but
# if the system has a larger number of interfaces or expected to
# communicate with a larger number of directly-connected neighbours,
# then it is recommended to increase this value.
net.ipv4.neigh.default.gc_thresh3=16384
net.ipv6.neigh.default.gc_thresh3=16384
Thanks to the switch chip, almost all traffic going through the switch will not be visible to the Debian side of the system. This does mean that you will not be able to use nf/iptables on forwarded traffic, however the switch driver does allow some Linux Traffic Control (tc) rules that use the “flower” system to be inserted into hardware, For example:
tc qdisc add dev swp1 clsact
# Rate limit UDP from port swp1 going to a IP address to 10mbit/s
tc filter add dev swp1 ingress protocol ip pref 10 \
flower skip_sw dst_ip 192.0.2.1 ip_proto udp \
action police rate 10mbit burst 16k conform-exceed drop/ok
# Drop TCP SYN packets from swp1 going to 192.0.2.2
tc filter add dev swp1 ingress protocol ip pref 20 \
flower dst_ip 192.0.2.2 ip_proto tcp tcp_flags 0x17/0x02 \
action drop
You can monitor the results of these rules using tc -s filter show swp1 ingress
# tc -s filter show dev swp2 ingress
filter protocol ip pref 10 flower chain 0
filter protocol ip pref 10 flower chain 0 handle 0x1
eth_type ipv4
ip_proto udp
dst_ip 192.0.2.1
skip_sw
in_hw in_hw_count 1
action order 1: police 0x7 rate 10Mbit burst 16Kb mtu 2Kb action drop overhead 0b
ref 1 bind 1 installed 3615822 sec used 1 sec
Action statistics:
Sent 3447123283 bytes 4481404 pkt (dropped 1920284, overlimits 0 requeues 0)
Sent software 0 bytes 0 pkt
Sent hardware 3447123283 bytes 4481404 pkt
backlog 0b 0p requeues 0
used_hw_stats immediate
...
Useful examples of flower rules include:
# Target UDP to a IP range
flower skip_sw dst_ip 192.0.2.0/24 ip_proto udp
# Target TCP port 80 to any IP
flower skip_sw src_port 80 ip_proto tcp
# Target all GRE packets
flower skip_sw ip_proto 47
You must ensure that you do not put skip_sw in your rule if you plan to drop packets, else your ACL could be bypassed if a packet was engineered to trigger a control plane punt.
I do not know any good utility to manage these rules for you, Instead I have a shell script that applies them on boot using a systemd service.
Since there are two sides (the CPU side and the chip side) to this switch, it is useful to monitor both of them, The driver keeps the regular kernel counters in sync with how much the chip is doing for you automatically:
# ip -s -h l show dev swp1
24: swp1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 1c:34:da:xx:xx:xx brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped missed mcast
2.01T 4.74G 0 0 0 214M
TX: bytes packets errors dropped carrier collsns
1.10T 5.78G 0 0 0 0
altname enp1s0np1
If you want to just know how much traffic a interfaces has been sent to the Atom CPU, you can run this:
# ip -h stats show dev swp1 group offload subgroup cpu_hit
24: swp1: group offload subgroup cpu_hit
RX: bytes packets errors dropped missed mcast
25.3G 264M 0 0 0 0
TX: bytes packets errors dropped carrier collsns
442M 5.14M 0 0 0 0
This 25GB here is roughly speaking the BGP traffic that the switch has done with the service provider since boot.
However if you are looking for counters on why data was sent to the CPU, you can run the following to get the counters:
# devlink -s trap | grep -v pci/0000:01:00.0 | paste - - - - | grep -v "bytes 0"
name ttl_value_is_too_small type exception generic true action trap group l3_exceptions stats: rx: bytes 20084104 packets 227812
...
name ipv6_ospf type control generic true action trap group ospf stats: rx: bytes 71177822 packets 591399
name ipv4_bgp type control generic true action trap group bgp stats: rx: bytes 1626384210 packets 3005173
name ipv6_bgp type control generic true action trap group bgp stats: rx: bytes 2128110217 packets 3538356
...
Because the network interface counters are automatically synchronised, you can use your normal monitoring tools on your servers, on this switch. My setup is a blend of collectd and prometheus node_exporter, both of these tools work fine:
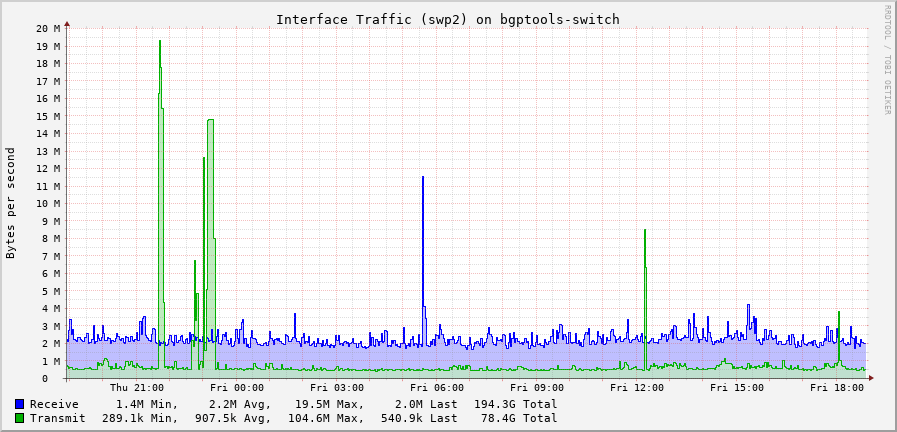
Normal packet sampling methods do not work on this switch, because as mentioned above the CPU side of the switch is nearly totally oblivious to most traffic passing through the switch. However this becomes a problem when you wish to do packet sampling for traffic statistics, or to drive something like FastNetMon for DDoS detection.
However not all is lost, hsflowd does support the driver’s “psample” system for gathering data.
My hsflowd config is as follows:
sflow {
sampling.10G=10000
collector { ip=192.0.2.1 UDPPort=6666 }
psample { group=1 egress=on }
dent { sw=on switchport=swp.* }
}
Since hsflowd has an incompatible software licence with most distros, you will have to build it yourself. However I find that once compiled, hsflowd automatically manages the tc rules required for packet samples.
I think this is incredibly nice hardware, with even more incredible open source drivers. However I do worry that Nvidia will fall down a similar path to the late Nortel at this point due to their meteoric rise in an industry that could easily be a bubble. For that reason it is worth calling out that they are not the only vendor with this kind of open source driver functionality.
Arista has a closed source driver like this where you can supplement parts of their “EOS” with your own parts, however it is nowhere near as complete as this. But it does allow you to run bird (or other routing software) on their products if you wish to retain control of the code powering of your routing protocols.
Marvell also apparently has drivers similar to mlxsw, I have yet to personally use such hardware, but Mikrotik is known to use this hardware, but right now has no official (or known) way to “jailbreak” the hardware to run your own software stack.
I hope this changes in the future, as Mikrotik’s hardware price point is very competitive, it’s just the software reliability that always turns me off their products, so having an option to not use RouterOS while keeping their very competitive hardware would be a huge deal.
I agree with Pim’s conclusion, this switch and its ecosystem is incredible. Good, and acquirable hardware combined with software that you have the power to fix yourself is currently unheard of in the industry, and mellanox delivered it!
This setup has been running without a hitch for bgp.tools for some time now, and I hope to keep it running until I outscale it one day, since I would be surprised if I need to remove it for any other reason.
I’d like to thank Pim van Pelt for their earlier post on these devices and Basil Filian for helping me figure out a number of quirks of these devices!
If you want to stay up to date with the blog you can use the RSS feed or you can follow me on Fediverse @[email protected]!
Until next time!











)